
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Kubernetes
- 인공지능
- image
- Type
- Python
- 영화
- lightly
- docker
- YOLO
- GenAI
- ultralytics
- 논문리뷰
- 클론코딩
- 엔지니어
- clone
- 리뷰
- Gemma
- llm
- FunctionGemma
- 파이썬
- 야호
- Ai
- container
- DART
- 구글
- Fultter
- 딥러닝
- Flutter
- coding
- chatGPT
- Today
- Total
딥러닝 공부방입니다. 근데 이제 야매를 곁들인.
[논문리뷰] MUM: Mix Image Tiles and UnMix Feature Tiles for Semi-Supervised Object Detection 본문
[논문리뷰] MUM: Mix Image Tiles and UnMix Feature Tiles for Semi-Supervised Object Detection
ZeroAct 2022. 3. 13. 16:22오늘은 Semi-Supervised Object Detection을 위한 strong augmentation을 제안한 논문을 리뷰하고자 합니다.
MUM : Mix Image Tiles and UnMix Feature Tiles for Semi-Supervised Object Detection
Many recent semi-supervised learning (SSL) studies build teacher-student architecture and train the student network by the generated supervisory signal from the teacher. Data augmentation strategy plays a significant role in the SSL framework since it is h
arxiv.org
해당 논문은 서울대학교 자회사인 스누아이랩에서 쓴 논문입니다. 역시 한국인이 쓴 논문이라 그런지 글이 잘 읽히는 것 같아 쉽게 읽은 것 같습니다.
Semi-Supervised Learning(이하 SSL)에 관심이 있으신 분들은 이 리뷰를 보고 논문을 직접 읽어보아도 좋을 것 같습니다.
서론
SSL에 대한 전반적인 내용을 전부 설명하기엔 지식이 부족하여 모르시는 분들을 위해 간략하게 설명 하겠습니다.
일반적으로 우리가 딥러닝 모델을 학습할 때는 많은 양의 labeled data가 필요합니다.
이미 많은 대규모 데이터 셋들이 있지만 실생활에서 풀고자 하는 문제의 대상들이 전부 등장하지는 않기 때문에 크게 유효하지 않을 수 있습니다.
또한, labeling 작업은 매우 비싸고 시간이 오래걸리는 작업이기 때문에 규모가 작은 회사나 조직에서 직접 많은 양의 데이터 셋을 구축하는 것은 매우 힘든 일입니다.
너무나도 당연하게도 적은 labeled 데이터로도 모델이 충분이 잘 동작하도록 학습시키려는 연구들이 많아지고 있습니다.
이제 Semi-Supervised 라는 이름이 와닿으시나요?
바로 논문에서 제안하는 MUM을 설명하기 보다는 Semi-Supervised Object Detection(이하 SSOD)이 어떤 메커니즘으로 동작하는지 짚고 넘어 갑시다.
이 논문에서도 baseline으로 삼고 있는 [2102.09480] Unbiased Teacher for Semi-Supervised Object Detection (arxiv.org) 라는 논문의 그림입니다.

1. Burn-In Stage
사용가능한(아마도 매우 적은) Labeled 데이터로 모델을 학습을 합니다.
2. Mutual Learning Stage
Unlabeled 데이터를 사용해서 학습합니다.
이때 Teacher의 가중치는 고정시킨 채로 target이 없는 이미지를 forward 합니다.
Burn-In Stage에서 이미 조금은 학습이 되어 있는 상태이니 무언가 예측값이 나오겠죠?
이 예측값으로 가짜 target 을 만들고 가짜 target을 예측하도록 Student를 학습시킵니다.
이 설명만 들었을 때, 이게 대체 무슨 의미가 있나 싶었습니다.
하지만 핵심은 Weak Aug.와 Strong Aug.에 있습니다.
Teacher는 약하게 Augmentation된 이미지를 forward 하고,
Student는 강하게 Augmentation된 이미지를 forward 합니다.
직관적으로 보면 Teacher가 쉬운 문제를 풀어서 정답을 내고,
Student에게는 같은 문제를 더 어렵게 만들어서 풀도록 합니다.
결국 답은 같지만 다른 난이도의 문제 쌍이 생긴 셈입니다.
여기서 중요한 것은 Strong Augmentation이 정답을 바꿀 정도로 강하면 안됩니다.
제 개인적인 생각으로 Strong Augmentation은 문제를 어렵게 만드는 역할도 있지만 Teacher가 놓칠 수 있는 부분을 감안해 주는 역할도 있을 것 같다는 생각이 듭니다. Teacher 자체도 매우 적은 데이터로 학습이 되었다 보니 배경이 아닌 곳을 배경이라고 할 수도 있겠죠? 이러한 영역들이 Strong Augmentation으로 인해서 배경일수도 있겠다 싶게 변한다면 아예 배경이 아닌 상태일때보다 더 이상적인 방향으로 학습이 될 것 같네요.
Teacher는 Student에게 답을 알려주는 역할을 하게 되고, Student는 Teacher보다 어려운 문제를 풂으로써 Teacher보다 유능해지는 기이한(?) 현상이 발생하게 됩니다.
Student의 가중치를 업데이트 한 뒤에는 Student가 Teacher보다 좋은 가중치를 가지고 있기 때문에 이제 Teacher가 Student의 가중치를 가져옵니다.
설명이 길었는데 다시 한 번 그림을 보시면 생각보다 단순한 메커니즘임을 알 수 있을겁니다.
MUM
MUM은 제목에 써있듯 Image를 섞고 Feature를 다시 원래대로 복원하는 방법입니다.

큰 구조는 Unbiased Teacher와 같지만 Strong Aug. 부분이 다릅니다.
Unbiased Teacher 논문에서 사용한 Augmentation은 다음과 같습니다.
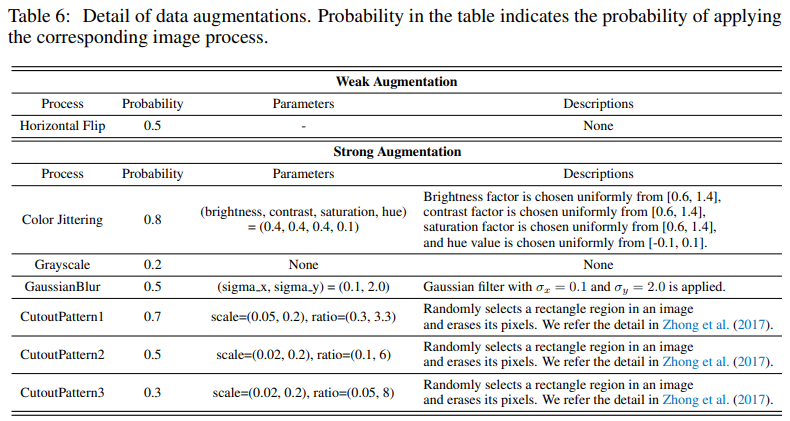
표를 보면 weak aug로는 horizontal flip만 사용하였고 strong aug로는 주로 색을 변화시키거나 픽셀을 랜덤하게 지우거나 블러를 하는 방법을 사용했습니다.
이미지의 geometry를 변형시키는 좀 더 강력한 augmentation을 사용하지 못하는 이유는 대상으로 하는 task가 Object detection 이기 때문에 Teacher가 생성한 pseudo label, 즉, 정답이 똑같이 유지되어야 하기 때문입니다.
MUM은 이미지 패치를 섞어서 특징 추출기에게 geometric 한 변형을 주게됩니다.
하지만, 특징 추출기 이후의 classification이나 regression을 하기 전에 원래 이미지와 같은 구조로 복원을 시키기 때문에 Teacher의 pseudo label을 그대로 유지할 수 있습니다.
Mixing UnMixing 을 그림으로 표현한 것입니다.
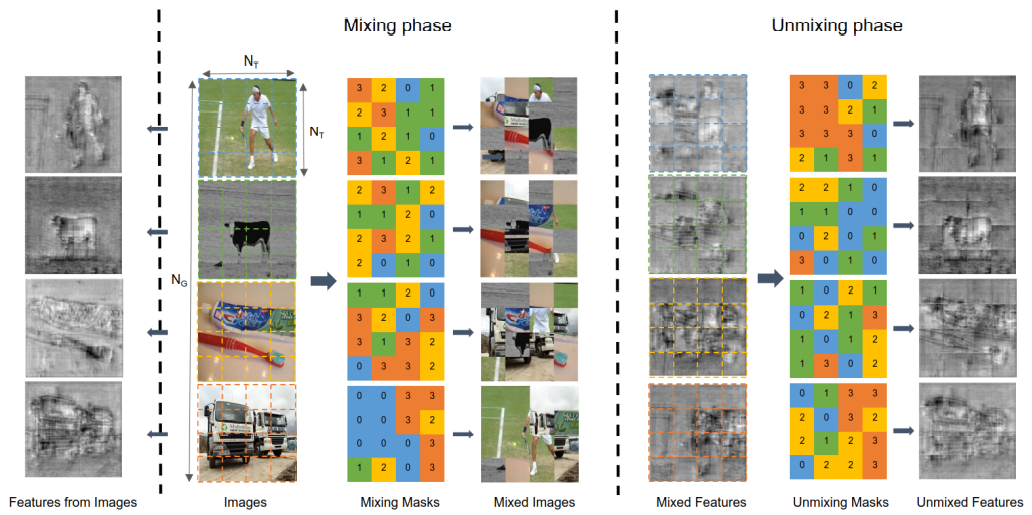
특징 추출기(backbone)는 Mixed Images를 입력으로 받고 Unmixed Features를 출력으로 나오게 합니다.
가장 왼쪽에 있는 Features from Images는 원본 이미지를 입력으로 주었을때의 특징입니다.
이 그림을 보고 Unmixed Features는 artifact가 생긴 것 같아서 오히려 안좋아 진 것 같다는 생각을 했습니다.
저자는 이 부분에 대해서 MUM의 Unmixed Feature는 mixing에 의해 각 tile이 local한 정보만 사용할 수 있게 되었고 feature가 degraded 되었다고 말합니다.
이로인해 student가 적은 단서를 가지고도 Teacher처럼 예측 하도록 만들어 기존 연구들의 weak-strong data augmentation에 대한 철학과 부합하다고 말합니다.
저는 weak-strong data augmentation이 backbone이 아닌 이후의 network를 잘 학습시키는데 집중한다는 느낌을 받았습니다.
결론
SSOD에서 사용가능한 Strong Augmentation 기법을 제안한 MUM 논문을 읽어 보았습니다.
SSOD부분에서 SOTA를 달성하였고, Object detection 뿐 아니라 Classification에서도 유의미한 성능을 보여준다고 합니다.
어떻게 보면 간단하다고 할 수도 있겠지만 재밌는 아이디어인 것 같습니다.
예전에 리뷰한 [논문리뷰] Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles (tistory.com) 이 논문에서도 느꼈지만 연구자가 직접 문제를 정의하고 그 문제가 너무 쉽지는 않은가, 너무 어렵지는 않은가 또는 합리적인가를 직접 고민하고 아이디어를 내서 실험하는 것이 참 멋진 것 같습니다.
인간관계에도 역지사지가 중요하듯 모델과도 역지사지의 자세를 가지고 연구를 하는 것 같달까나..
저는 논문리뷰를 작성할 때 뭔가 제 생각을 끼워 맞춰보려고도 하고 최대한 쉽게 설명을 하려고 하다보니 참 시간이 오래 걸리는 것 같습니다.
오래 걸리더라도 차라리 적게 올리겠습니다.
화이팅


