
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 딥러닝
- FunctionGemma
- YOLO
- 논문리뷰
- 인공지능
- GenAI
- llm
- Fultter
- container
- ultralytics
- image
- chatGPT
- 클론코딩
- 야호
- 구글
- docker
- 엔지니어
- lightly
- Flutter
- Python
- DART
- Kubernetes
- 리뷰
- Type
- Gemma
- 파이썬
- Ai
- clone
- 영화
- coding
- Today
- Total
딥러닝 공부방입니다. 근데 이제 야매를 곁들인.
[논문리뷰] Squeeze-and-Excitation Networks 본문
요즘 Transformer 계열의 무언가들이 막 쏟아져 나오고 있죠...
그중 CNN을 대체할 수 있다는 ViT 모델에 대한 연구도 매우 활발히 이루어 지고 있습니다.
추후에 An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale 논문도 다루게 될 것 같습니다.
이 Transformer라는 녀석은 Self-attention이라는 메커니즘을 전적으로 활용하는 모델입니다.
Transformer 관련 공부를 하면서 대충 입력이 뭐고 출력이 뭐고 계산이 어떻게 되고는 이해를 했지만,
본질적인 Attention 메커니즘이 와닿지 않았습니다.
Attention 자체는 Transformer 에서 처음 소개된 것이 아니기 때문에 관련 연구가 많이 있는데,
그중 인용횟수가 거의 1만회나 되는 Squeeze-and-Excitation Networks 라는 논문을 리뷰하려합니다.
아마 pretrained 모델을 사용하신 경험이 있다면 SE-ResNet 이런 이름으로 접해보셨을 것 같네요. ㅎㅎ
1 Introduction.
CNNs은 convolution 연산으로 구성됩니다.
이 연산은 공간적 정보와 채널간의 정보를 잘 섞어서 특징을 구성합니다.
최근 연구에서 CNNs에 의해 얻어진 representation을 특징들의 공간적 상관관계를 캡쳐하는 메커니즘을 사용함으로써 강화할 수 있다는 것을 보였습니다. (Inception Models)
본 논문에서는 채널사이의 상호 종속성(상관관계)을 명시적으로 모델링함으로써 네트워크에 의해 생성되는 representation의 질을 향상시키는 Squeeze-and-Excitation(SE) block을 제안합니다.
쉽게 말하면 중요한 특징맵은 강조하면서 덜 중요한 특징은 억제하는 특징 조절기 입니다.
SE block은 단순히 층 사이에 넣을 수 있습니다.
입력과 출력이 같도록 했기 때문이죠.
입력으로 들어온 특징맵들을 일련의 과정을 통해 중요한 channel을 강화 시키고 같은 크기의 특징맵으로 내보냅니다.
SE block의 역할은 층의 깊이에 따라 달라질 수 있는데,
앞 레이어에서는 class에 상관없는, 즉, task와 무관한 low-level representation을 강화하게 되고,
뒷 레이어로 갈 수록 task specific한 representation을 강화하게 됩니다.
이 개념은 예전 논문 리뷰에서 다룬적이 있으니 참고하셔도 좋을 것 같습니다.
[논문리뷰] Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles
오늘은 transfer learning을 위한 사전학습을 하는 아이디어를 제안한 논문을 살펴 보겠습니다. 이런 퍼즐 아시죠? 모델이 이 Jigsaw Puzzle 문제를 풀도록 학습하는 것이 사전학습에 도움이 된다고 합니
zeroact.tistory.com
3 Squeeze-and-Excitation Blocks.
SE Block을 수행하기 전에 Convolution Layer를 생각해봅시다.
쉬운 이해를 위해 그냥 output filter 수가 1개라고 가정합니다.
특징맵들이 이 Convolution Layer를 통과하게 되면,
출력은 입력 특징맵들의 Convolution 연산 결과를 모두 더한 하나의 특징맵이 됩니다.
때문에 출력에는 입력 특징맵들의 채널간의 연관관계(종속성)가 반영이 되기는 하지만,
filter에 의한 결과물이기 때문에 채널간의 관계는 본질적으로 명시적이지 않고 지역적 특징이 얽혀있습니다.
SE block은 이 채널간의 연관관계를 명시적으로 모델링해서 특징을 강화하고자 합니다.
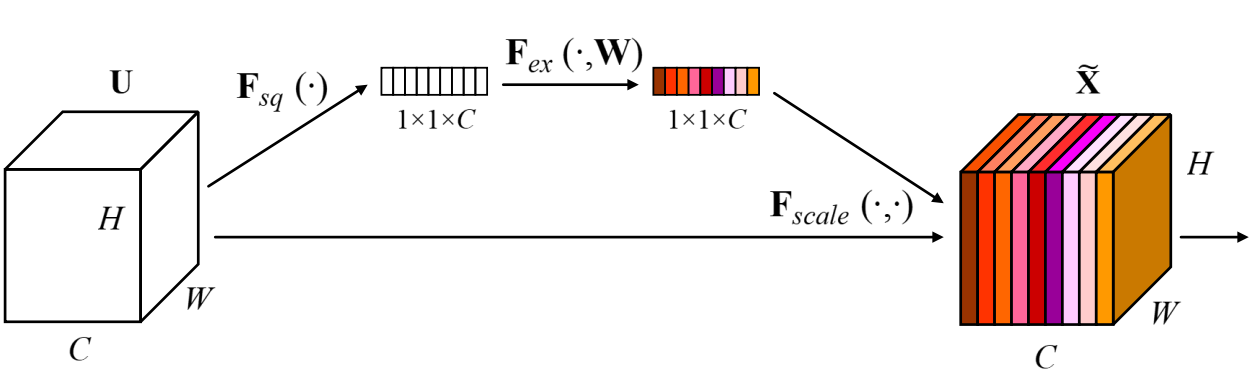
3.1 Squeeze: Global Information Embedding
Squeeze는 직역하면 쥐어 짜다 라는 의미이죠.
Convolution 연산의 결과물은 보통 3x3 filter를 통해 이루어 지기 때문에 전체 입력 특징맵의 특징을 담지 못합니다.
이 local receptive field 문제를 해결하기 위해 하나의 특징맵을 하나의 값으로 Squeeze 합니다.
어떤 방법을 사용하든 상관없는데 모든 값의 평균을 구하는 Global Average Pooling을 사용하는게 좋다고합니다.
이렇게 나온 하나의 값을 global spatial information으로 간주 할 수 있고,
이를 각 채널을 대표하는 descriptor 로써 사용합니다.

정리하면,
Squeeze를 통해 특징맵들이 전역적 지역 특징을 담고 있는 채널별 값들로 변환됩니다.
3.2 Excitation: Adaptive Recalibration
Excitation은 자극이라는 뜻입니다.
여기서는 Squeeze를 통해 얻은 채널별 값들의 의존성을 얻어내려고 합니다.
이때 두가지 조건이 있습니다.
첫째, flexible,
즉, 채널간의 관계가 단순하진 않으니 복잡한 관계도 커버할 수 있을 만큼 유연(복잡)해야한다.
둘째, non-mutually-exclusive,
즉, 하나의 채널만 excitation을 주지 말고 여러개의 채널에 다양한 excitation 줄 수 있어야한다.
두 조건을 만족하기 위해 다음과 같은 연산을 합니다.

z는 Squeeze한 결과입니다.
z와 W1과 곱하고, ReLU 사용하고, W2와 곱하고, Sigmoid를 사용하여 s가 나옵니다.
정리하면,
Excitation 과정을 하나의 sub network로 구성함으로써 충분히 복잡한 관계도 학습이 가능하고,
각 출력값들을 0에서 1사이로 변환하여 여러 채널에 다양한 가중치를 부여할 수 있게 됩니다.
그리고 Excitation 과정이 input specific 한 z를 가지고 이루어지기 때문에 본질적으로 input에 대한 조건을 띄는 dynamics 를 가지게 되어 Self-Attention으로도 생각해볼 수 있다고 합니다.
후기.
이 논문을 요약하면,
Convolution 연산의 결과물의 Channel 간의 관계가 spatial한 특징이 얽혀있어 명시적이지 않다는 문제가 있었는데,
spatial한 특징을 Squeeze하고 sub network를 사용하여 각 Channel의 중요도를 명시적으로 모델링하여 Excitation 했다.
과정 자체는 복잡하지 않지만, 이런 아이디어를 생각해 낸다는 것이 참 대단한 것 같습니다.
어떻게 동작하는지 잘 와닿지 않던 Attention 메커니즘이 아주 살짝은 더 이해되는 것 같습니다.
여하튼, 간단한 기법으로 당시 성능을 많이 끌어올린 SENet에 대해 알아 보았습니다.



