
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- chatGPT
- clone
- FunctionGemma
- Gemma
- 리뷰
- 구글
- GenAI
- 파이썬
- 인공지능
- Ai
- docker
- container
- 엔지니어
- 야호
- Type
- 논문리뷰
- image
- Kubernetes
- Python
- YOLO
- DART
- ultralytics
- 영화
- lightly
- Flutter
- coding
- Fultter
- 딥러닝
- llm
- 클론코딩
- Today
- Total
딥러닝 공부방입니다. 근데 이제 야매를 곁들인.
[논문리뷰] Unsupervised Cross-Domain Image Generation 본문
오늘은 Gan 논문 입니다.
Style Transfer와 기본적인 Gan에대한 지식이 있으시다면 읽으시는데 큰 어려움이 없을 것 같습니다.
0. Abstract
일단 domain 이 무엇인지 모르시는 분들은 웹사이트 들어갈 때 쓰는말 아닌가.. 하실수 있습니다만,
여기서 domain의 의미는 모음집 이라고 이해하면 편할 것 같습니다.
사실 정의하기 나름이라 기준이 모호한데요 예를 들어드리겠습니다.
예를 들면, 카메라로 찍은 사진들과 연필로 그린 그림들이 있고 이 둘을 구분짓는다면 다른 domain 입니다.
꼭 카메라, 연필로 구분되는 것이 아니라, 카메라로 찍은 사진들이 있는데, 초록 배경이 대부분을 차지하는 숲 사진과 하얀 배경이 대부분을 차지하는 북극 사진이 있다고 하면 이 또한 다른 domain으로 정의할 수 있습니다.
좀 더 넓은 도메인으로는 이미지 데이터와 음성 데이터도 다른 domain이라고 말할 수 있습니다.
논문 제목이 Unsupervised Cross-Domain Generation이죠.
그럼 카메라로 찍은 사진을 연필로 그린 그림으로 바꾸는 것을 하나? 라고 추측할 수 있겠죠.
게다가 Unsupervised라는 말이 있으니 Labeling도 없이 할 수 있나봅니다.
1. Introduction
사람은 서로 다른 domain 간의 변환을 잘합니다.
눈으로 실제 사람 얼굴을 보고 스케치할 수 있는 능력이 있죠.
하지만 컴퓨터는 그렇지 않습니다.
이런 사람의 능력 혹은 특징을 모방한 Gan, Style Transfer, Domain Adaptation, Transfer learning 등의 분야에서 활발한 연구가 이루어 지고 있습니다.
저자는 제안하는 모델을 사람 얼굴 사진을 이모지로 바꾸는 작업에 적용해 보았다고 합니다.
그 결과, 실제 사람이 이모지를 그리는 것보다 특징을 더 잘 잡아냈다고 합니다.
자세한 내용은 뒤에서 다루겠습니다.
2. Related Work
Gan
Gan을 모르신다면 Gan부터 보시는 것을 추천드리지만 그냥 보고싶으신 분들을 위해 간략하게 설명합니다.
Gan은 Generator와 Discriminator 모델 두개로 이루어져 있습니다.
Generator는 무언가를 생성하고, Discriminator는 Generator가 생성한 무언가가 그럴듯한지 판단합니다.
그럴듯한지 판단하는 기준이 무엇인가 예를 들어보겠습니다.
우리가 사람 얼굴을 생성하는 Generator를 학습 시키고 싶다고 할 때,
사람 얼굴은 가로 10, 세로 10 개의 픽셀을 가진 이미지로 생각해 봅시다.
가로 10, 세로 10개의 픽셀은 100차원의 공간을 의미하게 됩니다.
이미지 픽셀을 일자로 쭉 피면 100의 길이를 가지는 어떠한 벡터라고 생각할 수 있겠죠.
그래서 이제 우리가 가지고 있는 사람얼굴 데이터를 쭉 100차원 공간에 뿌려서,
아 사람 얼굴은 이런 분포를 가지고 있군, 이 사람 주변을 뽑으면 이 사람이랑 비슷한 사람이 나오겠네!
하면 참 좋겠지만 불가능합니다.
그래서 이 일을 Discriminator가 하게 합니다.
훈련 데이터의 분포에 있을법한 얼굴이면 1을 뱉도록, 아니면 0을 뱉도록 학습합니다.
Generator한테는 Discriminator가 1을 뱉도록 할만한 사진을 생성하도록 시킵니다.
잘 학습이 되면 Generator는 훈련 데이터에 있을 법한 사람 얼굴을 생성해 내게 됩니다.
저자는 Gan을 분포간의 동일성을 측정할 수 있는 도구로서 사용할 수 있다고 말합니다.
이해가 되시나요? (야매라서 죄송합니다.)
본 논문은 Gan에 새로운 제약을 추가하는 Conditional Gan의 한 종류입니다.
Condition을 어떻게 주는 지는 뒤에서 다룹니다.
Style Transfer
Style Transfer도 간략하게 설명하겠습니다.
방법이 여러가지지만 공유하는 주된 아이디어는 style loss와 content loss입니다.
이미지 분류기 학습이 잘 이루어 졌을 때 앞단의 layer에서는 엣지나 색 같은 low level 특징을 뽑고 뒷단의 layer에서는 global한 high level 특징을 뽑습니다.
style loss는 low level 특징을 유사하게 만들어 엣지나 색같은 특징을 비슷하게 만들고,
content loss는 high level 특징을 유사하게 만들어 이미지가 담고있는 대상을 같도록 합니다.
이 두가지 loss를 구하기 위해서는 이미 학습된 특징 추출기 모델이 있어야 합니다.
저자는 Style Transfer는 style에 집중한 반면, 제안하는 방법은 target space의 분포에 집중한다고 합니다.
또한, Style Transfer는 보통의 경우에 눈으로 보기엔 잘 동작하는 것 처럼 보이지만,
얼굴 사진을 이모지로 바꾸는 경우에 target domain의 속성이 약해집니다.
3. A Baseline Problem Formulation
이 파트는 Baseline 입니다.
Generator의 입력이 이미지가 들어간다거나 f가 어떻게 동작하는지 모호한 부분이 있는데 전반적인 이해에는 도움이 되니 살펴 봅시다.
제안하는 모델은 source domain에 해당하는 얼굴 사진을 target domain으로 바꿔주는 G를 학습하는 것이 목표입니다.
그러니까 Generator에서 나오는 결과물들은 target domain이어야 하는 것이고 Discriminator에 target domain에 해당하는 이미지를 넣으면 1이 나와야 하는 것이죠.
Gan의 objective function과 유사합니다.
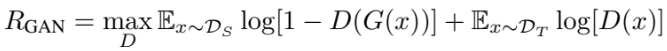
왼쪽항은 source domain에서 뽑은 얼굴 사진을 Generator에 넣어서 생성된 이모지 같은 사진을 Discriminator에 넣었을 때 출력값이 0에 가까워지도록 하고,
오른쪽항은 target domain에서 뽑은 이모지를 Discriminator에 넣었을때 출력값이 1에 가까워지도록 합니다.
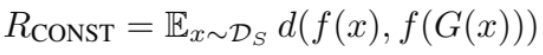
여기서 f는 encoder 라고 생각하시면 편합니다.
d는 거리를 쟤는 방법으로 MSE, L1 등 여러가지를 사용할 수 있지만 큰 차이가 없다고 합니다.
이 식은 source domain의 얼굴 사진이 f를 통과한 압축 벡터와 이모지가 되어버린 얼굴이 f를 통과한 압축 벡터가 같아지도록 합니다.
제 생각에는 content loss와 이름만 다르지 아이디어는 거의 비슷한 것 같으나,
저자가 앞에서 style transfer와 다르다고 열심히 강조 하셨기 때문에 일단 아니라고 합시다.
큰 아이디어는 이게 전부 이지만, 이렇게만 하면 성능이 잘 안나옵니다.
다음 파트에서 어떤 식이 추가되었는지 살펴 보겠습니다.
4. The Domain Transfer Network
일단 그림을 보고 각 L 들이 무슨 역할을 할지 예측해 봅시다.
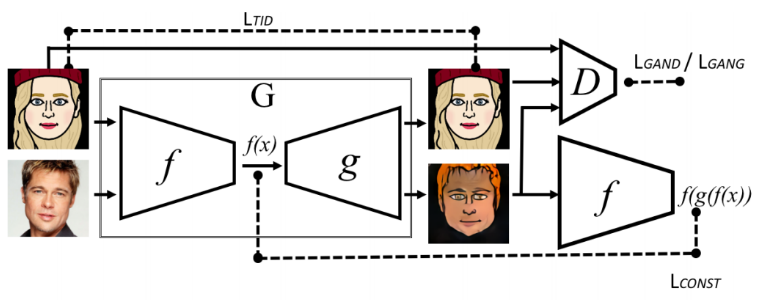
앞 파트에서 모호했던 f는 이미지를 입력으로 받고 출력을 g에 넣어주는 역할을 합니다.
그래서 Generator G는 이미지를 입력으로 받고 이미지를 출력으로 내어주는 역할이 됩니다.

Discriminator는 target domain인지 아닌지 판단하는 역할 이었는데, 이를 세 번 수행하여,
target domain의 이미지가 target domain 인지,
target domain을 G에 넣어 나온 이미지가 target domain인지,
source domain을 G에 넣어 나온 이미지가 target domain인지
를 판단합니다.
이는 학습시에 G의 output이 모두 target domain이 되도록 합니다.

Generator는 Discriminator를 속여야 합니다.
Generator의 output이 Discriminator가 1이 뱉도록 합니다.
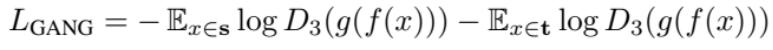
source domain의 이미지의 압축 벡터와 G를 통과한 이미지의 압축 벡터가 같도록 합니다.
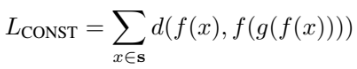
target domain의 이미지에 대해 G가 Identity function이 되도록 합니다.
target domain을 넣으면 완전히 똑같은 이미지가 나오면 베스트겠죠?
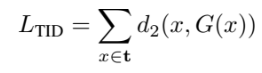
이건 제가 설명할 수 없어서 찾아보니 생성되는 이미지 품질을 좋게한다고 합니다.

5. Experiments

딱 보기에도 참 잘 동작합니다.
그리고 학습시에 source domain과 target domain에서 특정 이미지들을 제외해도 추론시에 얼추 생성해 냅니다.
다음 표는 SVHN 데이터 도메인을 MNIST 도메인으로 Transfer 하여 인식기를 학습한 결과입니다.
결과를 보면 source domain에 3을 제외했을 때는 성능 저하가 크게 없는 것을 볼 수 있습니다.
하지만 target에서 빠지면 영향이 큰 것 같습니다.
아무래도 생성되는 결과는 g의 능력에 의존하기 때문에 g가 생성해보지 못한 것을 생성하는 것은 어려워 보입니다.
그런데 source와 target 둘 다 3을 제외했을 때는 target에서만 뺀 것보다 좋습니다.
이는 source에만 있으면 source의 3을 다른 것으로 mapping하도록 학습 되었기 때문이라고 합니다.

저자는 Domain Transfer Network가 Style Transfer 보다 더 general 하다고 합니다.
즉, DTN을 Style Transfer 용도로도 사용이 가능하고, 얼굴 같이 content가 중요한 경우 더 중요한 경우 더 잘 동작한다는 것입니다.
개인적인 생각으로는 Style Transfer가 이미 학습된 네트워크에 의존적이고 DTN은 그렇지 않다는 점이 큰 것 같습니다.
Gan 기법을 사용하여 분포에 집중한 것도 크겠죠.
후기.
좋은 일이 생겨서 3일에 한 번 업로드 하겠다는 결심이 깨져버렸네요...
앞으로 꾸준히 올리려고 노력하겠지만 주기가 길어질 것 같아 걱정입니다. 하하.
지적은 감사합니다.
화이팅.



