
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |
- DART
- image
- Ai
- ultralytics
- 인공지능
- Type
- Kubernetes
- 파이썬
- Gemma
- 영화
- 엔지니어
- YOLO
- 딥러닝
- GenAI
- 논문리뷰
- chatGPT
- Fultter
- docker
- 클론코딩
- 리뷰
- Flutter
- container
- 구글
- lightly
- clone
- FunctionGemma
- coding
- llm
- Python
- 야호
- Today
- Total
딥러닝 공부방입니다. 근데 이제 야매를 곁들인.
[논문리뷰] Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network 본문
[논문리뷰] Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
ZeroAct 2022. 1. 16. 22:32요즘 Super Resolution을 공부하기 시작해서 앞으로 SR 관련 논문 리뷰를 하게 될 것 같습니다.
이 논문 이전에 base가 되는 논문들이 있지만, 내용이 딱히 어렵지 않아서 그냥 필요할 때 키워드만 찾아보면 될 것 같아서 건너뛰고 GAN부터 시작하겠습니다.
최근에 좀 바빠져서 이제 각 파트별로 자세히는 못 다루고 정말 핵심이라고 생각되는 부분만 골라서 리뷰하겠습니다.
Abstract
(2017년 기준) 최근 SR 모델들이 깊어지고 빨라지는 등 많은 발전이 있었으나,
upscaling factor가 클 때 어떻게 세밀한 texture를 복원할 것인지에 대한 문제는 여전히 남아 있습니다.
기존 optimization based 방법론 (L1, L2 loss 기반 최적화) 들은 PSNR에서는 큰 발전이 있었지만,
high-frequency detail 이 부족하고 perceptually unsatisfying 하다는 문제가 있습니다.
이는 기존부터 제기되어 오던 문제로 PSNR, SSIM등의 지표들이 사람이 느끼는 만족감과는 거리가 멀다는 것입니다.
그래서 SR 에 GAN 을 사용해보기로 했고, 진짜 사람이 평가하는 평가지표를 사용했습니다.
1. Introduction
기존 방법론 들은 PSNR을 최대화 시키기는 것을 목표로 삼았기 때문에,
PSNR과 직접적으로 연관된 MSE를 최소화 하는 방법들이 많았습니다.
이 방법은 편하고 직관적이긴 한데 pixel difference 기반으로 정의된 것이기 때문에,
결과물에서 perceptually relevant 한 difference 를 capture 하지 못해서 실제로 봤을때는 별로입니다.
계속 perceptual이라는 단어가 나올텐데, 쉽게 '눈으로 봤을 때'로 치환해서 읽으면 문제 없습니다. ㅎㅎ

이 이미지위에 각 (PSNR dB/ SSIM) 수치가 적혀 있는데, 세번째가 본 논문에서 제시하는 결과물입니다.
PSNR과 SSIM은 둘 다 높을수록 좋은 지표이지만, 눈으로 보았을때 세번째가 가장 선명해보일겁니다.
본 논문에서는 이렇게 perceptually appealing 한 결과물을 얻기위해서 perceptual loss를 사용합니다.
1.1.3 Loss functions
본 논문에서 가장 중요한 내용이라고 생각하고 뒷 부분은 이 loss function 들을 어떻게 활용했는지를 다룹니다.
MSE-based 와 GAN-based 가 어떻게 다른지 표현한 그림을 제공하고 있습니다.

우선, 빨간색 patch들은 Real data입니다.
GAN을 직관적으로 보면 random latent vector를 generator를 통해 discriminator가 진짜라고 할만한 real data distribution 혹은 manifold 상의 이미지 인 것 같은 fake data 를 생성해내는 것이죠.
이전 포스팅에서 GAN의 이러한 특징 때문에 discriminator를 어떤 두 도메인이 같은 도메인인지 다른 도메인인지 판단할 수 있는 도구로서도 사용될 수 있다고 언급한 바 있습니다.
[논문리뷰] Unsupervised Cross-Domain Image Generation (tistory.com)
그렇게 GAN-based Solution은 Natural Image Manifold 상에 있는 하나의 점이 됩니다.
하지만, MSE-based Solution은 real data와의 pixelwise difference의 평균을 최소화 하도록 설계가 되어 있습니다.
그림을 보면 가운데 파란색 patch가 MSE-based Solution이라고 나와있습니다.
해당 patch는 초록색으로 연결된 patch들과 pixelwise difference의 평균은 작을수도 있겠지만,
눈으로 봤을때는 뭉게져 보입니다.
개인적으로 해당 그림은 정말 쉽게 이해되도록 잘 그려진 그림인 것 같네요 ㅎㅎ.
그리고, VGG loss도 사용했습니다.
저는 VGG를 사용하는 개념을 Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization 논문을 통해 처음 접했었는데, 이 prior 때문에 해당 논문에서 왜 style loss가 아닌 content loss를 사용하였는지 와닿지 않더라구요.
어쨌든 본 논문에서는 VGG19 모델의 상대적으로 깊은 layer의 feature map을 사용한 content loss를 사용했습니다.
1.2. Contribution
- SOTA!
- perceptual loss를 최소화 시키는 GAN-based network SRGAN을 제안한다.
- MSE-based content loss를 VGG feature map based content loss로 대체했다.
- MOS (mean opinion score) 를 측정하여 큰 차이로 photo-realistic SR 문제에서 sota를 달성했다.
2. Method
Single Image Super Resolution은 high resolution을 예측하는 일입니다.
보통 원본 이미지를 Gaussian filter 나 interpolation 을 통해 low resolution 이미지로 만들어서,
다시 원본 이미지로 복원시키는 문제입니다.
이 논문은 비교적 예전 논문이라 real world 문제는 다루지 않지만 다음에 다룰 논문에서는 real world 문제도 다루고 있습니다.
그래서 SR 의 목적 함수는 다음과 같이 쓸 수 있겠습니다.
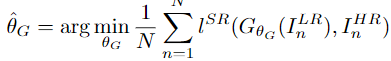
LR 이미지를 G를 통해 HR space로 복원시켜 지정한 loss function을 최소화 시키는 가중치를 찾는 문제 입니다.
본 논문에서는 perceptual loss로 여러 loss term들을 weighted combination 하여 구성했습니다.
2.1. Adversarial network architecture
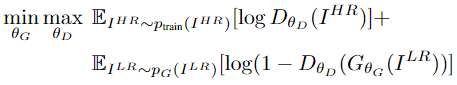
GAN에 대해서는 특별히 다른 내용은 없습니다.
다만, 앞에서 MSE-based 보다 GAN이 왜 더 texture 같이 high-frequency한 부분들을 잘 복원하게 되는지만 기억하면 됩니다.

Generator는 이전 SR 연구인 SRResNet을 사용했습니다.
2.2. Perceptual loss function
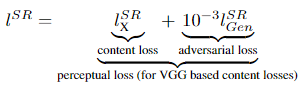
Perceptual loss 는 VGG19 의 feature map을 사용한 content loss와 adversarial loss의 조합으로 이루어 집니다.
비율은 content loss 1에 Gan loss 10^-3을 주고 더했네요.
2.2.1 Content loss
content loss 는 비교할 두 이미지를 VGG network에 통과시켜 특징맵을 비교해서 얻어집니다.
VGG를 사용하는 이유는 large dataset으로 이미 학습이 잘 되어 있고 쉽기(단순) 때문입니다.
CNN을 어느정도 공부하셨으면 아시겠지만 입력과 가까운 층일 수록 엣지나 색 같은 low level feature를
출력과 가까운 층일 수록 task specific한 high level feature를 뽑도록 학습이 됩니다.
이부분에 대해서 저의 직관적인 생각으로는 SR 은 아무래도 이미지가 어떤 object를 담고 있는지보다는
엣지, texture, 색 같은 low level feature가 중요하다고 생각해서 앞부분 layer를 사용할 것이라고 예상 했는데
그러면 용어가 style loss가 되어야하는 것이 아닌가 하는 의문이 있었습니다.
본 논문에서는 최종적으로 비교적 뒷부분 layer를 사용했습니다.
물론, 어떤 layer를 사용할 것인지는 하이퍼파라미터로 바꿔서 실험 가능합니다.

Content loss 부분은 Experiment 부분을 같이 보겠습니다.

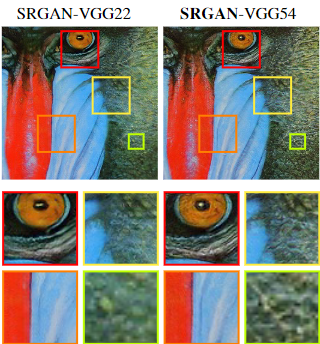
VGG22는 2번째 maxpooling layer 전의 2번째 conv layer를 사용한 것이고
VGG54는 5번째 maxpooling layer 전의 4번째 conv layer를 사용한 것입니다.
제 생각대로라면 VGG22를 써야 맞는데... Set5에서는 얼추 예상이 맞았지만
저자는 VGG54가 보통 texture를 더 잘 표현하는 경향이 있다고 합니다.
2.2.2 Adversarial loss
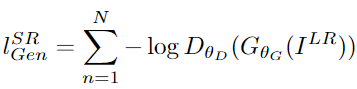
평범한 GAN의 Generator loss 입니다.
3. Experiments
3.2. Training details and parameters
MSE-based SRResNet을 학습시키고 이 가중치를 사용해서 GAN style로 이어서 학습했습니다.
처음부터 GAN으로 학습하면 학습이 불안정해서 실패를 했나봅니다.
3.3. Mean opinion score (MOS) testing
26명의 평가자에게 1(최악)부터 5(최고)까지 점수를 주게했습니다.
Set5, Set14, BSD100 데이터셋에 대하여 SR기법 12가지(SRGAN 포함)를 적용한 이미지를 보여줬습니다.

4. Discussion and future work
저자는 깊은 layer의 특징맵은 순수하게 content에 집중하고 adversarial loss가 texture detail에 집중한다고 추측합니다.
또한 ideal loss function은 application에 따라 다르다고 합니다.
예를들어, SRGAN으로 생성된 finer한 detail이 의료 분야에서는 안좋을 수 있습니다.
끝



