
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 엔지니어
- YOLO
- 야호
- Fultter
- 구글
- llm
- 파이썬
- container
- clone
- 리뷰
- chatGPT
- Gemma
- 클론코딩
- 영화
- DART
- ultralytics
- 논문리뷰
- FunctionGemma
- Flutter
- 인공지능
- lightly
- Kubernetes
- coding
- image
- GenAI
- Python
- docker
- 딥러닝
- Type
- Ai
- Today
- Total
딥러닝 공부방입니다. 근데 이제 야매를 곁들인.
[수학] Mahalanobis Distance 언제 쓸까 본문
평소에 사용하는 많은 Distance 들이 있지만 anomaly detection 분야를 공부하면서 이름이 괴상한 Mahalanobis Distance라는 놈을 만났습니다.
이 Distance가 어떤 의미이고 언제 써야하는지 간략하게 느껴보겠습니다.
언제나 그랬듯이 야매입니다.
식
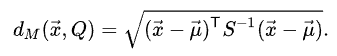
점 x와 분포 Q사이의 거리인데 공분산 역행렬 S^-1이 추가 되었습니다.
공분산 역행렬을 빼면 Euclidean Distance와 동일합니다.
의미
"어떤 점과 분포 사이의 거리"

초록점과 파란 분포사이의 거리를 어떻게 구할까요?
가장 가까운 파란점과의 거리를 구할 수도 있겠지만,
분포와의 거리니까 특정 점보다는 분포를 대변하는 어떤 특정 값을 사용하여 거리를 구하는게 조금 더 자연스러울 것입니다.

파란점들의 평균에 빨간점을 찍었습니다.
이제 초록점과 빨간점사이의 Euclidean 거리를 구하면 초록 점과 파란 분포사이의 거리를 구한게 될 것입니다.
이제 거리를 구하긴 했지만 뭔가 찜찜한 부분이 있습니다.
이게 진짜 분포와의 거리를 구한 것이라고 할 수 있을까..?

초록점과 보라점은 빨간점과 비슷한 거리에 있기는 하지만 보라색 점을 파란색 분포와 가깝다고 말할 수 있을까요?
Euclidean Distance와 Mahalanobis Distance간의 어떤 차이가 있는지 보겠습니다.


분포와 가까운 점 500개를 시각화 한 결과입니다.
Euclidean Distance는 단순 좌표상의 거리만 가지고 Distance가 결정되지만,
Mahalanobis Distance는 파란 분포의 모양이 고려되어 Distance가 결정됩니다.
용도
대부분의 경우 데이터의 feature vector의 원소는 scale도 다르고 분포도 다릅니다.
예시 데이터의 경우 x축으로 길고 y축으로 짧습니다.
Mahalanobis distance를 사용하면 이런 상황에서 좀더 이상적인 거리를 구할 수 있습니다.
주의점
공분산의 역행렬은 Positive Definite Matrix 여야 합니다.
이 말은 공분산의 역행렬이 존재해야한다는 의미이고,
이는 공분산의 column 들이 선형 독립이어야 한다는 의미 입니다.
Deep Learning 모델에서 나온 feature vector를 사용하여 Mahalanobis Distance를 바로 구하려고하면,
아마 무조건 nan 값이 발생할 것입니다. (numpy 기준)
Deep Learning Feature 는 서로 독립적이라는 보장이 없기 때문입니다.
만약 이런 상황에 처하신다면 PCA 같은 기법을 사용하여 Feature dimension을 줄여서 Distance를 구하시면 원하시는 결과를 얻으실 수 있을겁니다.
감사합니다.
소스코드 예시
def mahalanobis(data, pts):
mean = np.mean(data, axis=0)
cov = np.cov(data.T)
inv_cov = np.linalg.inv(cov)
distances = []
for pt in pts:
mean_zero = pt - mean
inner = np.dot(np.dot(mean_zero, inv_cov), mean_zero.T)
distances.append(np.sqrt(inner))
return np.array(distances)
'딥러닝 > 기타' 카테고리의 다른 글
| FunctionGemma 엔지니어링 1 (0) | 2025.12.27 |
|---|---|
| [Active Learning] Lightly ai, Active Learning 이란? (1) | 2023.03.01 |
| YOLO 가 세상을 지배한다!!! (4) | 2023.01.23 |
| [ChatGPT] 입으로 TODO App 개발 (0) | 2023.01.01 |
| Auto Encoder와 Variational Auto Encoder의 직관적 차이 (1) | 2021.12.18 |



