
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- llm
- Gemma
- docker
- Type
- Python
- FunctionGemma
- 리뷰
- 클론코딩
- 파이썬
- 인공지능
- lightly
- 딥러닝
- 영화
- chatGPT
- Ai
- coding
- DART
- 엔지니어
- ultralytics
- Flutter
- 구글
- Fultter
- 논문리뷰
- image
- GenAI
- Kubernetes
- YOLO
- clone
- 야호
- container
- Today
- Total
딥러닝 공부방입니다. 근데 이제 야매를 곁들인.
[Active Learning] Lightly ai, Active Learning 이란? 본문
본 포스팅은 lightly ai 블로그 글의 요약 + 사견을 담고 있습니다.
An overview of Active Learning methods (lightly.ai)
An overview of Active Learning methods
Learn about the advantages and disadvantages of Active Learning methods and which of them solves your problem.
www.lightly.ai
Why Active Learning?
라벨링에는 돈과 시간이 든다.
요즘엔 데이터를 수집할 수 있는 환경이 아주 잘 구축 되어있다.
하지만, 그 데이터를 전부 라벨링하고 저장하고 관리한다는 것은 현실적으로 불가능하다.
그래서 수집된 상태의 데이터, 즉, Unlabeld Data를 모두 사용하지 않고
모델이 최고 성능을 낼 수 있는 Subset을 고르는 것이 Active Learning 의 역할이다.
Research Directions
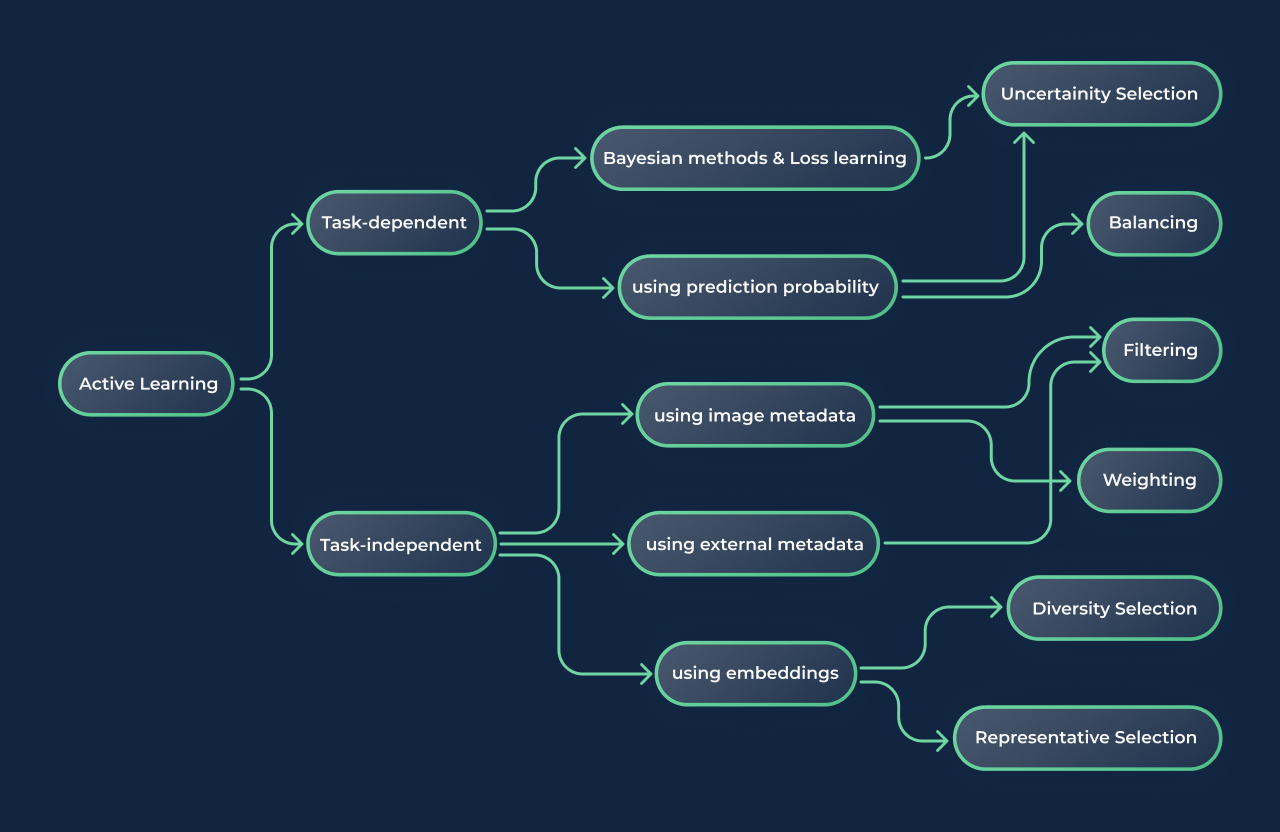
내가 좋아하는 기업중 하나인 lightly ai 에서 이렇게 research directions 을 그려주셨다.
이 분야를 처음 접하지만 대충 어떤 연구들이 진행되었고 진행중인지 쉽게 파악할 수 있었다.
모든 기법의 상세 내용은 위에 링크를 참고 하시면 좋을 것 같고 큰 갈래에 대한 요약만 합니다.
1. Task-dependent active learning

task 종속적인 active learning 은 task 와 class 가 정해져 있는 경우이다.
그림에서 볼 수 있듯 이 갈래의 기법들은 loss 나 prediction 을 사용하기 때문에 초기 모델이 필요하다.
초기 모델을 학습 하기 위해서 전체 데이터의 일부분을 랜덤 샘플링해서 학습하는 과정이 필요하다.
Using prediction probabilities (모델 예측값 사용하기)
전체 unlabeled 데이터들에 대한 prediction 값을 얻은 후, uncertainty 를 통해 selection 을 수행하는 방법이다.
여러 방법이 있지만 공통적인 철학은 동일하다.

모델이 어려워 하는 데이터, 즉, decision boundary 에 가까운 데이터를 골라서 모델을 학습하는 것이다.
이렇게 sampling 된 데이터를 hard samples 라고 한다.
하지만, hard sample 은 성능을 저하 시키는 여러 요인이 있다.
첫번째,
어려운 데이터일수록 사람이 보기에도 애매한 데이터 일 수 있고,
그렇기에 label noise나 정말 미묘한 차이에 민감해 질 수 있다.
또한, boundary 주변의 데이터만 학습하게 되면 high-signal feature 를 놓칠 수 있게 된다.
(high-signal, 정보량이 많은, 목적을 위해 꼭 필요한, 중요한 정도로 해석하면 된다.)
lightly 에서 이를 잘 표현하는 그림을 그려주었다.
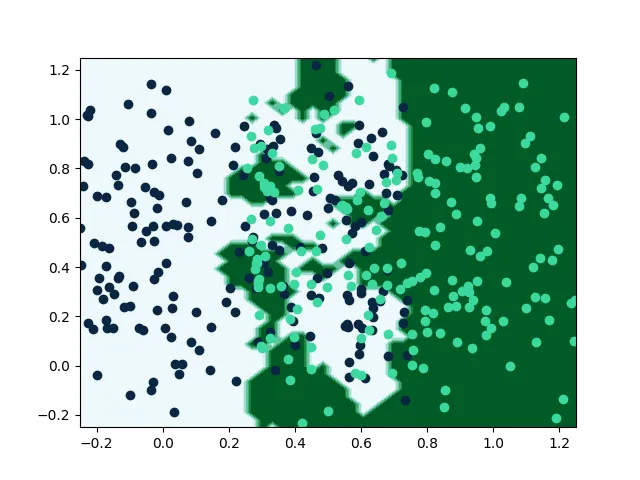

Bayesian method & Loss learning
두번째,
deep learning 모델은 자기 자신의 uncertainty 를 제대로 평가하지 못한다.
익히 알고 있는 overconfident 문제와 비슷한 맥락인 것 같다.
그래서 모델의 plain prediction 을 사용하지 않고 loss 를 사용하는 기법이 등장했다.
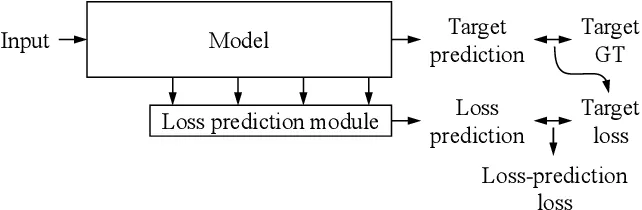
uncertainty 자체를 학습하는 개념이다.
(자세한 내용은 생략, 대단하신 한국분이 쓰신 논문이라 반가웠다. 루닛)
Drop out 을 통해 variance 를 uncertainty 로 간주하는 BALD(2017) 라는 논문도 있다.
아쉽지만 당연하게도 이 방법들도 완벽하지는 않다.
추후 이런 문제를 커버하는 최신 논문을 리뷰해 볼 예정이다.
2. Task-independent active learning

task 독립적인 기법들은 task 와 class 가 모두 정해지지 않은 상태에서 사용할 수 있는 기법들이다.
벌써 막연한 느낌이 들지만 무엇이 있는지 보자.
Metadata-based active learning
이 방법은 딥러닝을 사용한 것은 아니다.
말 그대로 Metadata (촬영된 시간, 날짜, 선명도, 휘도 따위) 를 통해 sampling 을 하는 방법이다.
이 방법으로 실무 문제에 적용한 적이 있는데 나이브 하지만 꽤 좋은 방법이다.
Embedding-based active learning
Self supervised learning 을 통해 feature 를 잘 뽑는 모델을 학습하고 feature embedding 을 사용해 sampling 하는 방법이다.
이후의 방법은 uncertainty 기반 방법과 크게 다른 것 같지는 않다.
Diversity Selection
마찬가지로 embedding 을 사용한 방법으로 최대한 다양한 feature를 가지는 데이터를 뽑는 방법이다.
일반적으로 넓은 커버리지를 가지는 데이터셋을 구축하는 것이 좋다.
랜덤 샘플링이 성능이 꽤나 좋은 이유가 이 때문이라고 생각된다.
Representative Selection
엣지 케이스를 무시하고 주요 대상들을 잘 예측하는 것이 중요한 케이스에 사용하는 방법이다.
unlabeled 에서 비슷한(대표되는) 데이터를 뽑는다.
결론
The dream team when it comes to combinations are Uncertainty Selection and Diversity Selection.
여러가지 방법을 잘 섞어 사용하는 것이 좋다.
'딥러닝 > 기타' 카테고리의 다른 글
| FunctionGemma 엔지니어링 2 (0) | 2025.12.27 |
|---|---|
| FunctionGemma 엔지니어링 1 (0) | 2025.12.27 |
| YOLO 가 세상을 지배한다!!! (4) | 2023.01.23 |
| [ChatGPT] 입으로 TODO App 개발 (0) | 2023.01.01 |
| [수학] Mahalanobis Distance 언제 쓸까 (0) | 2022.09.16 |

